🔥 Improvements of fuzzing techniques in Vuzzer
Hi, this is my report of my academic internship at the University of Bristol’s Cyber security group.
This Cyber security group works on many projects to protect computer systems. One of them is Vuzzer, a program that tries to discover vulnerabilities independently within applications. This project helped the cyber security community, but there is still a lot of features that could be added to make it more powerful.
It’s in this context that I was charged to improve the existing software, in order to make it more effective. My report shows the results of my contribution.
You can find Vuzzer64++ here : https://github.com/whereisr0da/vuzzer64
1 - What is Vuzzer
1.1 - Overview
The fuzzing is a software bug test technique that aims to find bugs in applications by testing random inputs. A fuzzer is a software that generate and test a big amount of input in loop on an application to make it crash, in order to find bugs that can lead to a vulnerability.
Vuzzer is a new generation fuzzer, that tries to generate more efficient inputs and prioritize application parts to test. It tries to learn about how an input can travel deep path in the application to test the code’s part that can be vulnerable. By mutating the input, Vuzzer is able to avoid error handlings and generate inputs valid enough to cross the common error detection, and test the real input usage in order to find bugs.
The difference between Vuzzer and other fuzzers like AFL, is that it tries to understand how an input affect the execution path in the application, and how the input can be modified to cross more functionalities of the target program.
Vuzzer is a greybox fuzzer, a fuzzer that works with a binary executable (without the source code) and handle it through assembly machine code.
This fuzzer is only testing file input command line programs. Each time Vuzzer will test an input, it will launch the target application with the input to test in argument.
Vuzzer work with a loop, at each iteration, it will test a set of input on the target program and see how it reacts to them. Each round, an input will travel a special path in the application, this path is represented by the list of Basic blocks executed during the processing of the input. So, if an input travels a big list of basic blocks, this means that this input has a better chance to test the real program functionality than the others.
At each loop, Vuzzer prioritizes application path by giving a score to each basic block, and the computation of the basic block score indicate if the path is better than another. If some inputs traveled a deeper path (high score) in the application than the last one, this mean that Vuzzer discover a new set of basic blocks that can lead to new ones in the next loop. So those inputs are used in the next loop in priority to maximize the chance of new discoveries.
Vuzzer tries also to avoid error handling made by the target program. By doing a first round of loops with known good inputs, and a second one with false inputs, Vuzzer can define error handling basic blocks by subtracting the bad path made by the false inputs by the good ones. Error handling blocks are marked with a negative score, and if an input path travels through it, the input is no longer considered due to its score.
One of the main aspects of Vuzzer is its input mutation. It learns about how the input has gone passed through each comparison instruction of the target application, to define values that should be in the input to cross error handling blocks.
Vuzzer use Dynamic taint flow analysis, to know which offsets of an input are used and where. Taint analysis will output a list of comparisons (containing the offsets of the input) made by the target program in function of an input. This will give the offsets of the input that are used by the program and the values that the program used to make the comparison. And with this, Vuzzer is able to understand how the target program behavior interacts with an input.
1.2 - Environment
Vuzzer is based on a lot of technologies such as binary instrumentation, static analysis and dynamic taint flow analysis.
Here is a schema to present Vuzzer environment :
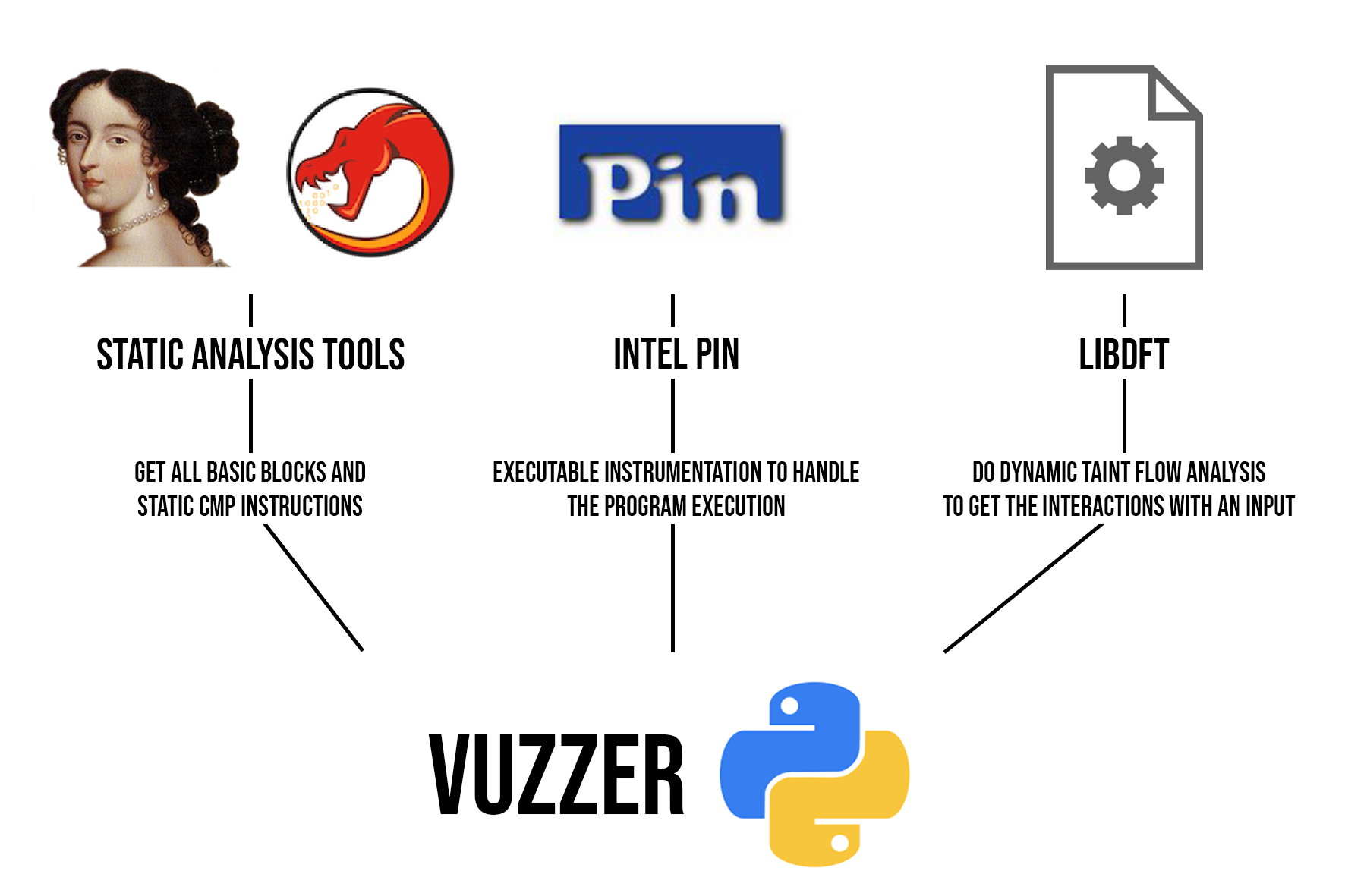
Figure 4 - Vuzzer environment
The main Vuzzer program is coded in python, it handles all the things regarding input manipulation and input selection optimization. Static analysis tools like IDA or GHIDRA will extract all the basic blocks and all the cmp (comparison) instructions of the target application. Intel Pin will handle the test application execution through instrumentation, and specially handle crashes and exceptions. Libdft will mark cmp that compare memory data to our input data.
Here is a schema of the Vuzzer environment while it tests an input :
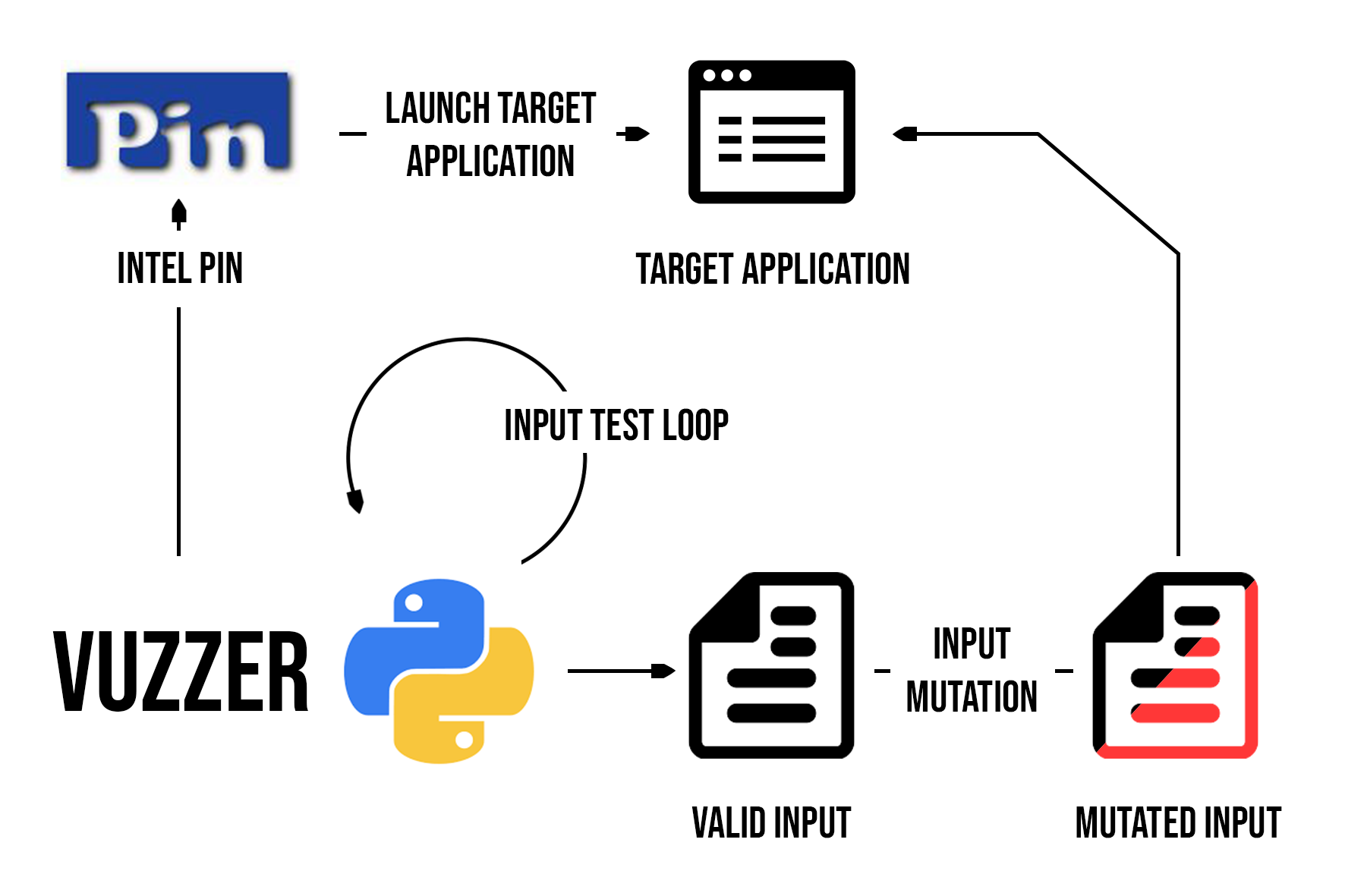
Figure 5 - Input test environment
1.3 - How does it works
Vuzzer uses a lot of mechanisms to work, and to understand my improvements, I need to define how does it work in details.
First of all, it has to register all basic blocks of the target application and their score, to get an overview of the possible execution paths. It also looks at all cmp instructions through static analysis output, to know comparison values that will be used later to mutate inputs.
After this, it starts the first round of loop with the “dry” turn, this will test the target application with known valid inputs and collect their path. After that, Vuzzer will test bad inputs, and by subtracting the bad path made by those inputs, it will know which blocks are error basic blocks. It also calculates each score (weight) of each block of the program (error basic blocks will have a negative score).
Next, it will do dynamic taint flow analysis with Libdft on known valid input paths. To extract some magic bytes in function of cmp instructions marked earlier, and lea instructions memory offset, to get more input offsets used by the target program. The dynamic taint flow analysis will be enabled again only if new basic blocks are discovered (taint analysis will be on inputs that made the new path).
Now Vuzzer will create files based on known valid inputs by applying mutation / modification to them.
There are two types of modification applied to the inputs, random actions (called input mutation) and taint-based changes. The first generates a random set of actions (delete, add, change bytes) to apply to the input with random values. And the second one applies more specific changes related to taint analysis, like the cmp instruction values (values compared to an offset of the input). And lea memory offsets of the input (random values placed at the offset on the input use in lea instruction). Taint-based changes are static values that could be magic bytes, or bytes that the input should have to be valid. If some of those comparisons are common to all of the tested inputs, those are separated from taint-based changes and are called “Most common” changes. There will be applied at the end of the mutation process on all the inputs like magic bytes. Vuzzer also detect values that slightly change during each loop, and try to apply them to the input. There are called “More common” changes.
There are also crossover inputs that, like their name says, are just mutated inputs that are mixed with others in order to make new ones.
All those new inputs are called initial population, and will be used in the first round of knowledge loop.
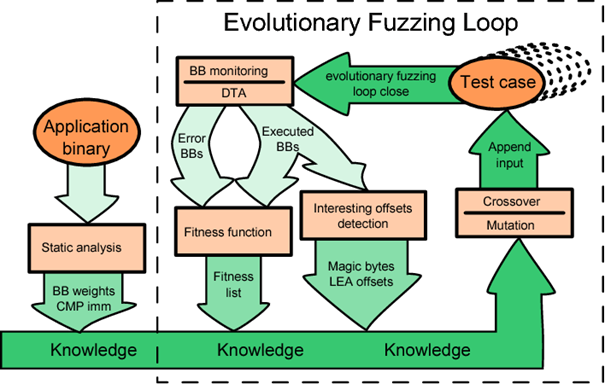
Figure 6 - Vuzzer knowledge loop : researchgate.net
Vuzzer will now test each of those inputs and see how the program react to them (error return code, crash reported by Pin). If a crash appears, the input that made the crash is copied to a special folder and the user is informed about it.
After the end of the loop, all traveled block scores of each tested input will be analyzed. If there are new basic blocks traveled compared to the last loop turn or good inputs dry loop turn, Vuzzer will launch those inputs called “specials” with taint analysis enabled. To extract additional information (magic bytes, new cmps, ….) and prioritize their utilization in next loop turn. For all of the other tested inputs, the “fitness” calculation function that defines their scores will select only inputs that have the most chance to travel deeper path in the next loop. And as I wrote before, if a score is negative, the input traveled error handling blocks, so it will no longer be considered.
So all of those selected inputs are mutated again, like above in the file creation, and the fuzzing loop will do another turn with them. And that’s it, Vuzzer will do loops until the user stops it.
Here is a schema of how Vuzzer loop work :
1.4 - Improvement ideas
My job in this project, was to improve the software and make it more efficient, and more efficient means increase the Vuzzer ability to explore the executable. So in other words, my goal is to increase Code coverage of inputs. There were a lot of aspects that could be changed in the implementation regarding this objective. My supervisor and myself, studied the subject and we found these modifications.
-
Mutation process loop through each offset of the input that have been compared in memory. Instead of looping through each offset, Vuzzer could loop through each tainted compare instruction, in order to avoid repetition, conflicts and to understand how mutate the input efficiently by analyzing the comparison.
-
Vuzzer mutates an input by applying random actions to it that could change its size. This will make conflicts with taint-based changes that stand on static offsets. So, the improvement could be to take care of each taint-based comparisons in this process, to make random actions that take into account comparisons size, to keep the input flow.
-
Taint flow analysis is good to find magic bytes, but in some cases, this analysis can flag comparisons that aren’t good to use. For example, in a loop process, if a program loops through a buffer, and compares the increasing offset value to a static number, like to get the end of a string with a null character. Taint analysis will mark all immediate comparison numbers (in this case null) as magic bytes, but they are not. So, the improvement could be to identify patterns of following comparisons, and take decision about them.
-
Conflicts between two offsets in the same input mutation are frequent, the strategy could be to create an input, each time a conflict occurred, that would contain the mutation without the conflict.
-
Taint flow analysis makes a list of data comparison in runtime that indicates where Vuzzer mutate. There are a lot of exception cases of comparisons that are not handled by Vuzzer and can possibly make input repetition.
-
An input list has a code coverage scope, Vuzzer use a home-made function to take the best inputs with best coverage. The idea is to implement a plugin, AFL-CMIN for another fuzzer called AFL, that handle this function very well to improve the input selection.
-
After a while in the input test loop, Vuzzer starts to use inputs with deep path that lead to error handling block, the idea is to see if avoiding those inputs make the fuzzing more effective, and if so, implement an option to avoid those inputs.
-
Inputs are stored as files, and the file opening process is slow, the idea would be to get the input file in memory to gain test time.
-
I saw a plugin called Lighthouse for IDA, a reverse engineering tool, that can show the code coverage of an input in the executable. By highlighting in green basic blocks that have been executed during the test of the input, this plugin allows to clearly see where Vuzzer had trouble passing the checks. The idea could be to export code coverage in the plugin format at each iteration of a taint analysis.
2 - My contribution
2.1 - Introduction
Considering my internship duration, I had to choose what improvements I should do in function of my available time. Because all the improvements described above were not achievable in this period of time. My plan was to implement the most important things to improve Vuzzer. This includes changing the comparison representation to consider cmp size in taint-based changes and mutation. Changing actions applied to input during mutation, find a way to handle conflicts (the biggest part in my opinion) and identify patterns in comparisons to handle special cases. I had time to do the AFL-CMIN input reduction, so I implemented it as well.
Here is why I think they are important :
-
Changing comparisons representation is very important because after this, Vuzzer could use a lot of information about a mutation regarding it’s cmp, like the size of the comparison, it’s offset in memory etc…
-
Changing actions during input mutation is very important because currently, Vuzzer applied unnecessary actions to input like described above (deleting, adding, …). Removing this and considering comparisons in the process will highly change the input mutation in the right way.
-
Conflict handling is also an important thing, because they are frequent, and not handled currently. Avoid them could help Vuzzer to make more accurate inputs.
-
Pattern detection could be better to handle complex cases when Vuzzer is stuck in mutation. It could also be the base for a community system, where contributors can submit their own patterns to help Vuzzer behavior.
-
AFL-CMIN reduction could be a good thing to implement because it can highly reduce the input count to test, by selecting only relevant inputs. It could make Vuzzer faster on its way of launching test.
About the order, changing comparison representation was the first thing to do because, all others improvements would benefit from it. Changing actions applied to input is the second thing to do because it’s a little improvement that can highly change the Vuzzer results, and could blow up every next improvement result if it is implemented after them. Next, Vuzzer will be in a good state to implement conflict handling, because of new mutation actions and cmp representation. And at the end, pattern detection and AFL-CMIN reduction could be implemented on top of it as good improvements options.
But before doing anything, I had to find a sample program to run Vuzzer. And make some default statistics to define the current state of Vuzzer (in terms of code coverage) that helped me to measure each of my improvement.
2.1.1 - My test program
Finding a software to compile in 64bit and test was easy, but finding one that Vuzzer could explore deeper at each loop iteration was complicated.
I first look up LAVA Dataset, used to test the original Vuzzer and compare its results with AFL. But I didn’t find any easy sample to test, without having a lot of lib to include in Vuzzer, or with an evolved exploration like explained above.
I was lucky to find Libjpeg source code, because it’s a Linux library that can be compiled as a standalone executable called “JPEG”. So it was easier for me to make my tests, and by chance, Vuzzer during each knowledge loops, explored step by step more of the executable. JPEG executable is doing a lot of checks regarding the file structure, and JPEG files could have a lot of special cases that make the header and file structure diversified. So it was a good sample to begin with and I used it for all my tests and development.
2.1.2 - Base statistics
So after setting up Vuzzer for Libjpeg, I tested it with 11 loop rounds (5500 inputs) 3 times in the same conditions. To get a default statistic to compare, if any of my modifications improve the fuzzing process. Considering that my goal is to increase code coverage, the indicator that could be the most efficient to analyze in all my report is basic block number.
To avoid bad result interpretations, this test and others will be done on the same virtual machine. An Ubuntu 64bit with a 4-core processor virtualized with Intel VT, and with 8Gb of RAM (RAM is important to make Libdft and Intel Pin work correctly).
Here are the results I got from Libjpeg with the old Vuzzer :
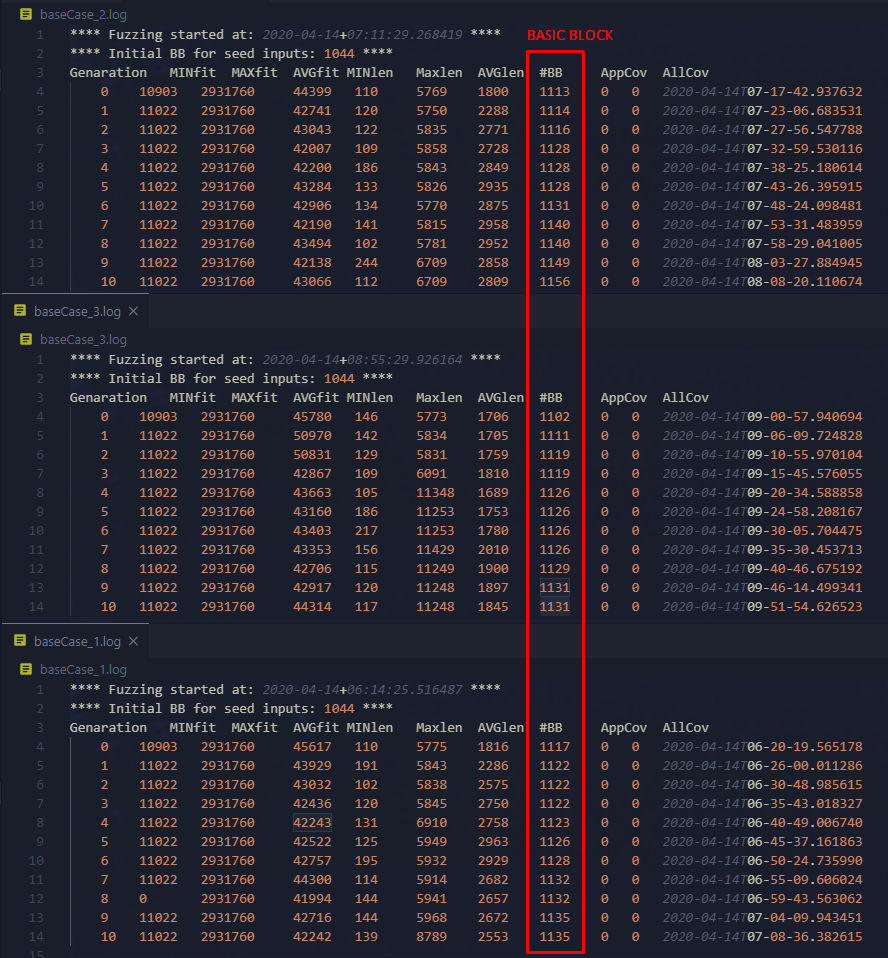
Figure 7 - First statistics with original Vuzzer
The block average of the 3 tests is ~1140 blocks after 11 loops, nothing can be interpreted from this right now. This will be the code coverage that I will use to mark each of my improvement.
Notice that the time is not a good element to consider, because each computer has different power. So I will use the loop count only when the input count is the same for each loop, and input tested if the input count is different between each loop.
2.2 - Changing taint bytes representation
First of all, I had to modify the comparison parsing in order to improve the mutation process later. Because the old implementation didn’t pass some important information about comparisons, that we need to improve mutation. Again, all those modifications have the goal of increasing code coverage, and it’s this vector I will use to follow the progression of my modification.
2.2.1 - Current LIBDFT output parsing and selection
So, I had to reimplement the all comparisons parsing, because the old structure only gets interesting input offset during comparisons. And get the compared value if the comparison is confirmed usable (comparison input data to immediate value for example).
An immediate value is a compared value in a cmp instruction that is contained in the instruction. This kind of instructions is made by compilers when the developer compares something dynamic to a static value, like this :
if(buffer[0] == 0x41) => cmp eax, 0x41
This kind of comparison can be for example magic bytes, and are used in taint-based changes or most common changes. Vuzzer handles more than immediate comparisons to do taint-based changes, but it is the one I will use in all my report to explain taint-based changes.
Comparisons made by the target application are stored in a cmp.out file that looks like this :
64 mem imm 0x4211d3 {4,5} {4,5} {4,5} {4,5} {} {} {} {} {} {} {} {} {} {} {} {} 0xe 0xd
32 reg imm 0x421274 {3} {3} {3} {3} {} {} {} {} {} {} {} {} {} {} {} {} 0xe0 0xe0
8 reg imm 0x420a46 {6} {} {} {} {} {} {} {} {} {} {} {} {} {} {} {} 0x40 0x4a
8 reg imm 0x420a59 {7} {} {} {} {} {} {} {} {} {} {} {} {} {} {} {} 0x46 0x46
8 reg imm 0x420a6c {8} {} {} {} {} {} {} {} {} {} {} {} {} {} {} {} 0x49 0x49
8 reg imm 0x420a7f {9} {} {} {} {} {} {} {} {} {} {} {} {} {} {} {} 0x46 0x46
8 reg imm 0x420b45 {11} {} {} {} {} {} {} {} {} {} {} {} {} {} {} {} 0x1 0x1
. . . . . . .
Each line is a comparison made by the target program :
-
The first number is the register size of the comparison
-
The two words following are the comparison type (line 1 : comparing something in memory with an immediate value).
-
The next number is the memory address of the comparison (cmp instruction).
-
And the 16 “bytes” following are the taint statue of the comparison in the two registers (8 bytes each, x64). It contains offsets of the input that are used in the compared value.
-
And the two values at the end are compared values.
So to clarify the 16 bytes of taint statue, the left first 8 bytes are the taint statue of the left operand / value in the comparison, and the right ones are the taint statue of the second operand.
For example, the line 3 is a comparison on one byte (8 bits register), between a value in a register and an immediate value (so the immediate value is the right one 0x4a). And the tainted offsets of the input are in the left operand of 16 bytes registers, so the first compared value (0x40) is the value of our input.
The old Vuzzer parsing is looping through each line of the cmp.out file and only extracts the input offsets and the compared value of each comparison. But it has access to a lot of information that are not used in the old Vuzzer. In order to use them I made a python object called cmpOperation that will parse each comparison information in the line.
2.2.2 - Reimplementation
Like the original Vuzzer, I handled 3 cases of comparison, where there are values that could be extracted to be applied to the input in taint-based changes. The immediate comparison and memory, registers strict comparisons.
-
Immediate comparisons store, like I wrote above, in one of the two possible operands, a hard-coded value that could be used to define magic bytes.
-
Memory and registers strict comparisons that compare two values contained in two memory addresses or registers.
There is no improvement to see right now, because I just changed the cmp representation. But, because we no longer store values for a single tainted offset as key (like old Vuzzer does), this implementation produces a huge cmp object count compared to the original code.
My implementation is flexible, because if another contributor would like to add new things like cmp instructions that could lead to new magic bytes, it will be easier to do. Now I handle input offset patterns detection, from my perspective it’s impossible to take efficient decisions about it, but if someone would want to, this would be now possible.
This implementation will certainly, makes loops through special parts of the cmp more difficult to handle, if someone tries to modify it after me. But there is no way I could make this better regarding looping through a list of comparisons.
I had to modify most and more common bytes algorithms, and a little bit of input mutation and taint-based algorithms. But because of my cmp object disposition, looping through cmp input offsets is not comfortable.
2.2.3 - Some speed improvements
During my test, I saw that the cmp.out file has a lot of duplicated lines (cmp instructions called). This means that the same data is checked multiple times, at the same place in memory with same values every time, by the same cmp instruction. It could be explained by a looping algorithm, like a while true or a for loop that checks a condition every time this the same value.
So I thought it could be a good idea to remove them. But this could be a problem regarding Comparison pattern identification, because it has to define if there is a loop algorithm and try to mutate the input accordingly. If I remove duplicates, there are no loops / patterns anymore.
So I implemented this as an option, because if someone uses Vuzzer without pattern detection, this could help him to make cmp parsing faster on big programs (example ffmpeg).
Because removing duplicated lines and create cmp objects only from those lines is significantly faster. Instead of looping through, as an example, 118221 lines, Vuzzer loops through 8436. It only saves a little bit of the calculation time to read the cmp.out file, but it improves the taint offset definition process.
2.3 - Input mutation improvement
After reimplementing cmp representation, I can change the input mutation in function of our new needs.
3.3.1 - Action optimization
3.3.1.1 - Concept
Like I said earlier, Vuzzer was made to be a Proof of concept, so its mutation process uses all kinds of actions to be applied to the input as a demonstration. For example actions that aim to eliminate random bytes in the input, adding random bytes, shrink the input in two parts and merge them in disorder…
Deleting or adding random segment of the base input is not good in my opinion for a lot of reasons. First, this action will break the entire input size, and will probably make old mutation knowledge useless. Secondly is that static taint offset changes like magic bytes will potentially override other important / random data, so input mutation is not accurate. Taint-based changes could just be erased or be applied out of the file scope due to deleting, and if a special byte is somewhere because of a special file structure, this will also be erased.
So, my idea was to only make random changes overriding over existing data, to keep the file architecture. Vuzzer will no longer add and remove part of the input, if it has to change 4 bytes, it will override 4 bytes of the input until the file has the space for it.
Also, from now, each mutation will no longer be applied on a random offset in the input. Now each mutation is done on a comparison offset Vuzzer stored earlier. And with this, one of the biggest changes here will be that each time an action is performed, this will care about the size of the comparison. If Vuzzer applies a mutation on a cmp input offset, the mutation will be about the size of the register used during the comparison. So, in theory, mutation will be more effective because, it will respect the same size used by the compared value, the size that the value should have.
But while I was testing my code, I saw that the register size and the value size are not the same sometimes. For example, a program could read a 1-byte integer and, while comparing it, use it in 4 bytes register comparison (the byte value is computed to 4 bytes word). So, in other words, taking the comparison size of the value instead of the register is more accurate.
2.3.1.2 - Implementation
So it was not very hard to do considering that now, offsets became comparisons. And comparisons store everything Vuzzer needs to handle this more effective approach of mutation.
The old version of Vuzzer was only making 2 or 3 mutations per input (the input mutation process can be called multiple times on the same input). So to make this thing more flexible, I made an option that could control the number of mutation per call of the mutation process on the input.
Currently I have implemented one action called “change_bytes” that like its name says, only change bytes, according to comparisons of taint analysis. To reduce conflicts and duplicates (see Conflicts handling), I decided to store the taintmap (object that contains all the taint comparisons) locally to remove applied mutations from taintmap once they are applied.
2.3.1.3 - First conclusions
After doing some tests, it appeared that Vuzzer travel more basic block than before. At the fourth-generation loop, I got around ~1167 basic block used by my inputs, compared to ~1140 at the 11th generation loop with the original program. This is not unexpected, considering that removing and adding bytes will destroy the file structure.
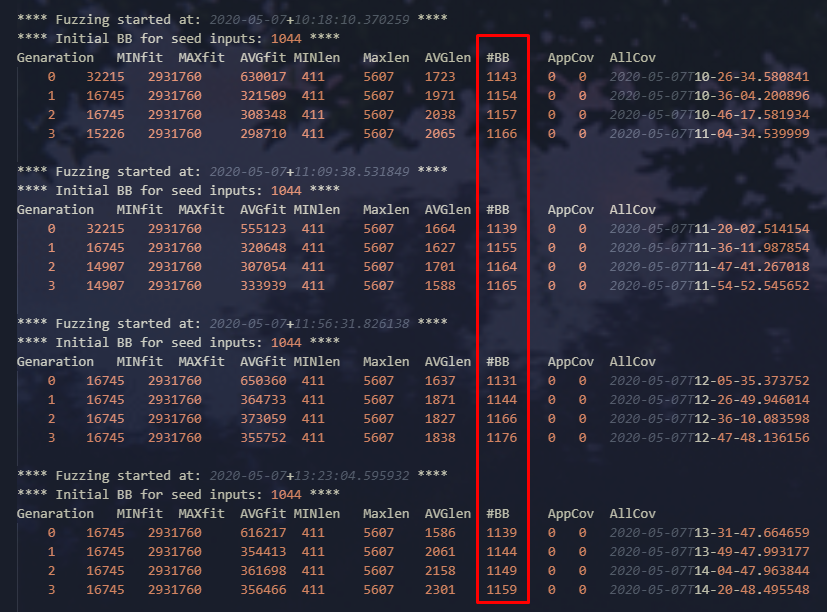
Figure 8 - Results of input mutation actions optimization
2.3.2 - Conflicts handling
My supervisor told me that Vuzzer doesn’t see what it doing with mutations, it just finds offsets where to apply mutation without considering that an older one could be there. And handle this important aspect of the mutation could be something that can improve Vuzzer results.
2.3.2.1 - What is a conflict
To explain what is a conflict and how handle it, I made a short scenario and schemas to represent how mutation works.
Context, here we have an input that will be used to apply 2 mutations.
The gray part represents the input split into parts (bytes) with, for each of them, its position (offset) in the input. The green part is the mutation 1 with a size of 2 bytes, applied on the input at the offset 2.
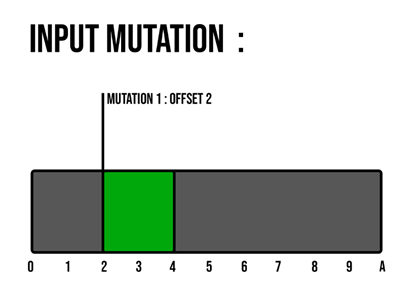
Figure 9 - Input mutation : first mutation applied
Now come the mutation 2 in amber, with a size of 4 and applied on the offset 3. But there is a problem, the mutation 1 already wrote the part of the input from offset 3 to 4, so here it’s a conflict (marked with red).
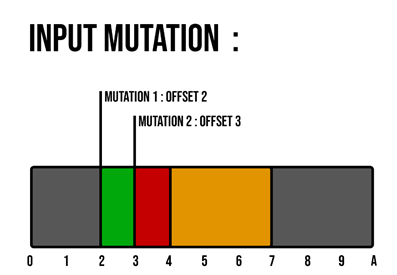
Figure 10 - Input mutation : second mutation applied
2.3.2.2 - Possible solutions
So, I had 2 ideas to fix this issue, the first one is to create 2 separated inputs each time there is a conflict. One input with the old mutation that is already applied, and one without the old one, and with the new one that do the conflict applied.
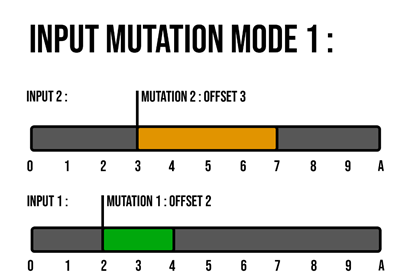
Figure 11 - Input mutation : child input creation algorithm
And the second could be to shift each offset depending of the first applied mutation. But during my implementation, I concluded that this idea will not be effective at all. Considering that Vuzzer will only take care of cmp input offsets to mutate, this will only break the file architecture like deleting and adding earlier actions.
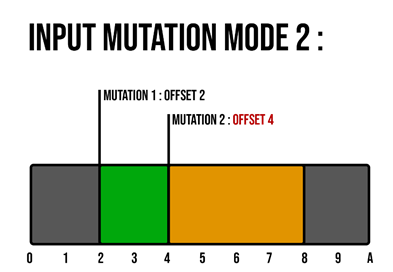
Figure 12 - Input mutation : offset shifting algorithm
2.3.2.3 - Child input creation algorithm
This is a strategy I created to handle conflicts, it uses the idea of splitting the input into two pieces shown above. By keeping an input without applying the mutation that does the conflict (the parent), and create an input that contains the conflicted mutation (child input).
And each time a mutation is performed on the parent input, each child will try to perform the same mutation. With that, Vuzzer could test a large number of inputs that could cover a lot of mutation possibilities.
Here is a schema I made to illustrate my strategy :
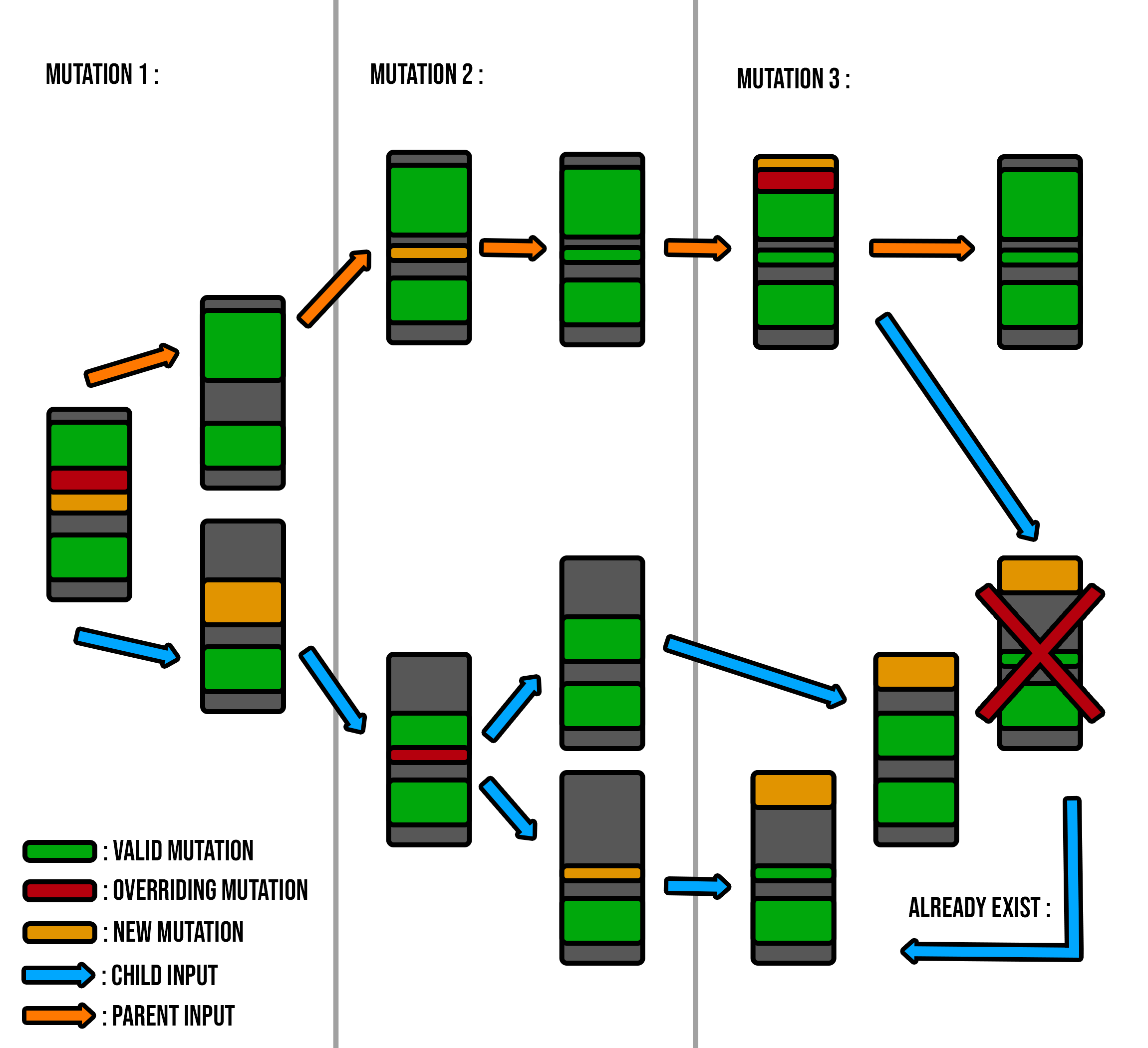
Figure 13 - Child input creation algorithm evolution
The schema illustrates the evolution of an input (parent) and, how it handled conflicts during the modifications of 3 mutations.
Like above, grey blocks are inputs, green segments are mutations already applied, yellow one’s are new mutations currently being applied, and the red ones are the conflicts between already applied mutations and currently applied ones.
The orange path represents the parent input during each mutation, and the blue one represents the evolution of each child input.
First in the mutation 1, there is a conflict, so the parent input will not have the conflicted mutation applied on it. And a child input will be created, with the already applied mutations, but without the one that was in conflict with mutation 1. And instead of that one, the mutation 1 is applied.
So now, there is a child input that takes care of this special conflict case and the original input, without overriding any data.
In part 2, the mutation 2 will successfully be applied to the parent input without conflicts. So, no child will be created, but at the same time, the mutation 2 will be tested on the child created in mutation 1. And here there is a conflict, so the child input will create a new child like above with the parent input.
And in part 3, this time the parent input will not receive the mutation 3 because, there is a conflict. So, a new child input will be created, and the mutation 3 will be tested on each children already created. But in this case, the child input created by the parent input already exists in the children list, so it is not added to the list.
2.3.2.4 - Implementation
This algorithm can create a decent count of child input very quickly, its complexity (if there is conflict and child input created) is about log(x). Without a limit, for 500 input, Vuzzer will generate about ~500 000 child inputs (I stopped before my vm crashes), so I added an option to limit the child input population.
Theoretically, child input will always be different, but if one day, a parent input has the same comparisons on each knowledge loop. Theoretically the first 500 child inputs will be the same (500 is the limit of child input). Because each comparison leads to a mutation and possibly a conflict. So if the mutation offset is always the same, we create the same child input in the child limit range. To avoid this, I made an option that controls the creation probability of child inputs. If sometimes, a child input is not created due to this random probability, the 500 generated children will not only be the first 500 child possibilities (see complexity above).
First, I thought it was a good idea to apply this algorithm to input mutation and taint-based changes (LEA and CMP). I didn’t implemented / applied, this algorithm to taint based changes for those reasons :
-
Because of conflicts between mutations and taint-based changes, taint-based changes have to be at static offsets, because they should be there in the comparison. So, it’s not necessary to use this algorithm here.
-
Because of conflicts between each CMP, it appeares that there are not that many conflicts, so creating 2 additional child inputs to the already big child list is not very important and probably a waste of calculation time.
-
And regarding LEA, the set of LEA instructions of the lea.out tainted flow analysis is always about 1/100 of the cmp.out size. So, there are always conflicts between LEAs due to the sample size, and if I implement the algorithm for this thing, it will double the number of child Input without a big accuracy of input mutation. It’s only my point of view due to my tests, I could be wrong about this.
As a security, the algorithm will check if there is a conflict within tainted CMP and LEA, but this doesn’t appear frequently. Also, I saw that sometimes, not applying cmp taint-based mutations to the child input (only most and more common applied) can produce better results. So, I made an option to apply cmp and lea taint-based changes to child inputs.
2.3.3 - Results
There are no big differences between the common results and child input generation results. The only things that changed is the number of inputs. Now Vuzzer can test large input numbers that are still legitimate, because each input is a possibility provided by a conflict.
During my tests, I saw that there is a difference of 1 or 3 blocks between normal generation, and child input generation. This is not enough to be considered as an improvement regarding exploration. But now Vuzzer handle conflicts, and this is the goal of my algorithm.
If you want to see my final conclusion about this, check Child input algorithm and AFL-CMIN reductions.
2.4 - Comparison pattern identification
2.4.1 - Introduction
First, let’s clarify what Vuzzer need to do :
-
A pattern representation that will be compared to the raw cmp.out file (contains all the comparisons information)
-
A way to handle a found pattern (executable code that can interact with the comparison list)
For the pattern representation, I was searching the best way to implement it. And the more I looked into to it, the more I was thinking that the best way to do it is to implement my own pattern representation language / grammar.
I was thinking about YARA, a pattern language made to compare malware signatures, because it has an implementation in python. But it’s not really appropriate to this case, because I needed variables to compare the pattern. I was also thinking about doing it with Regular Expressions, but for the same reason, it will be too complex to make an implementation of variables on top of Regex and control everything without bugs.
So I came to the conclusion that I should make my own representation of pattern to properly handle my needs.
About handling a pattern, I first looked around python evaluation, and python interfaces, but at the end, the easiest way to do it is to let the user handle the comparison list. And to give him, a python file could execute a function when the pattern is found, that allows the modification of the comparison list.
When I started programming, I thought this pattern detection could be executed only one time. After valid inputs taint analysis, but each input is different, and each comparison list made by the target program is different. And sometimes, a pattern can be found only after a lot of loops (due to the input improvement). So, I decided to apply it after each taint analysis (each time Vuzzer discover a new path with an input).
2.4.2 - Pattern representation
A cmp.out output looks like this :
32 mem imm 0x000000421c4a {0} {0} {0} {0} {} {} {} {} {} {} {} {} {} {} {} {} 0xff 0xff
32 mem imm 0x000000421c53 {1} {1} {1} {1} {} {} {} {} {} {} {} {} {} {} {} {} 0xd8 0xd8
32 reg imm 0x000000421d2a {1} {1} {1} {1} {} {} {} {} {} {} {} {} {} {} {} {} 0xd8 0xfe
32 mem imm 0x000000421a28 {2} {2} {2} {2} {} {} {} {} {} {} {} {} {} {} {} {} 0xff 0xff
32 mem imm 0x000000421a88 {3} {3} {3} {3} {} {} {} {} {} {} {} {} {} {} {} {} 0xfe 0xff
32 mem imm 0x000000421a91 {3} {3} {3} {3} {} {} {} {} {} {} {} {} {} {} {} {} 0xfe 0x0
32 reg imm 0x000000421d2a {3} {3} {3} {3} {} {} {} {} {} {} {} {} {} {} {} {} 0xfe 0xfe
. . . . . . .
So, I had this idea of representation :
32 $B imm $C $D(INC_NEW_LINE) $D $D $D * * * * * * * * * * * * $NOT($VAL) $VAL
WHILE_SAME_LAST_PATTERN_LINE(4)
32 $B imm $C $D $D $D $D * * * * * * * * * * * * $VAL $VAL
A pattern will be defined by a list of lines, each line defines a condition.
2.4.2.1 - Literal representation
A line is a set of elements that define how each element of a cmp.out line should be, static values (string that should not change) can be set like above with 32 and imm, and ignored elements can be set with the char *.
There are variables defined by a $ followed by its name, if the variable is not registered (first time seen in the pattern), its value will be set to the value saw at its place in the cmp.out. And otherwise the value at its place should be the same as the variable one to validate the pattern.
Variables can be initialized with an argument that indicates how the variable should evolve. For example, here, the $D variable uses INC_NEW_LINE to verify that the value in cmp.out should be increased at each new line of the pattern that contains $D.
Functions can be used too, to define more abstracts things like in this example WHILE_SAME_LAST_PATTERN_LINE (4). This indicates that the same pattern line defined above in the pattern, should be duplicated for the next lines at least 4 times.
Conditions can be used, like with the $NOT($VAL) that setup a variable that will have a value, that should be not equal to the variable $VAL. And with the special variable name NOT, this variable will not check the comparison between the value in cmp.out, and the value in variable like others.
The complete documentation of each elements of this representation will be made in the github repo.
2.4.2.2 - Representation goal
So, in this example, I want to define the followed pattern :
-
All comparison on 32 bits registers with immediate values on the second operator
-
That loop through an increasing offset of the input
-
That ends on a successful comparison
In other words, this pattern is a loop through a buffer of our input that ends only on a special condition, like a loop through a string while the character is not null (null terminator).
2.4.2.3 - How Vuzzer currently handle this pattern
In this specific case, Vuzzer will handle each value in $VAL as a valid byte for taint-based changes, and will apply them to input, but it’s wrong and will probably lead to an error handling. It is why pattern detection can improve Vuzzer if contributors take the time to define detected patterns during application tests.
2.4.3 - Implementation
To talk a little bit about it, validation works by testing the pattern on each line of cmp.out. And the validation process is executing each pattern lines, and if one cmp.out line doen’t match the pattern, it jumps to the next line.
My implementation loop through my cmpObjects representation, I don’t know if looping through line of cmp.out is more efficient than looping through objects, but for now, it seems fast.
2.4.4 - Comparison list modifications
So, after this, I had to find a way to handle a pattern after its detection. Like I said above, I will use python script files to allows the user to handle its pattern. It could be improved in the future by changing its representation.
A pattern definition file (python file), will get a set of patterns (like shown above) in separated text files. And each time a pattern of that set is found, a function of the pattern definition file is called. And will apply whatever the user wants to do to the input and comparison list, before any processing of Vuzzer.
2.4.4.1 - What the user could do if the pattern was found ?
The pattern ‘effect’ function is called before separating valid cmps for taint-based modification, from cmps applied at input mutation. Effect function has access to the cmp list before any sorting and interpretation.
So, with the first example I explained above (string detection), if this pattern is found, the user can delete those cmps for taint-based changes. And replace or modify them by valid values that end by the end byte wanted by the program loop.
2.4.4.2 - Implementation
Here is an example of pattern implementation : Pattern file example
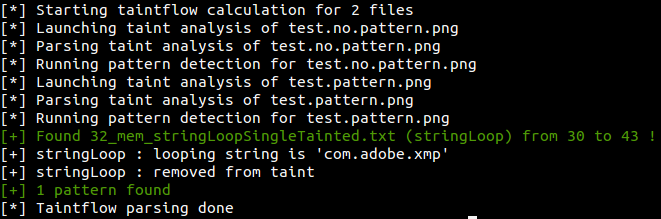
Figure 14 - Pattern detection (custom cmp.out for demonstration purposes)
Regarding my Libjpeg sample, I didn’t find a pattern that could be fixed / handled properly. So I can’t figure out an improvement for this part about Libjpeg. In my future Test suite, I will definitely test this, and see if there is an improvement.
2.4.5 - Code AFL-CMIN input selection
AFL is a fuzzer coded in C, which is pretty fast due to its low-level language. It has a plugin called AFL-CMIN that, if you give it a list of inputs, will test the target program with each of them, and will output the best ones in terms of code coverage. The idea was to implement this as an input reducer, Vuzzer produces a lot of files (parent, child inputs) and AFL-CMIN reduces this count to something faster to calculate.
I decided to implement this as an option, and split the reduction in two parts, standard inputs generation reduction (parent input) and child inputs reduction. Note that this reduction is only applied on inputs created from generation (inputs kept from other generation are not reduced).
There is not that much code to cover in this part because it’s only a launcher (AFL-CMIN launch code).
For both input generation, there is good reduction results.
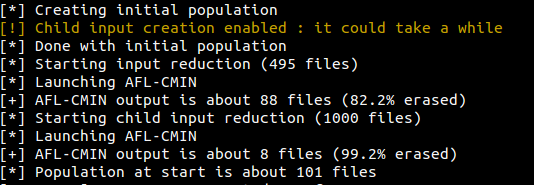
Figure 15 - AFL-CMIN input reduction
But there is one conclusion that result from this, child inputs discover less blocks than the normal generation does. To find an explanation about this could take a long time, but I have a theory about it. It’s maybe because child inputs become too similar at a certain point. If Vuzzer is about its 10th mutation on an input, and there are 40 child inputs generated for this input. If there is a conflict for each child, child inputs created will be a slightly different copies of the existing ones. And this could be the case at each mutation loop on the parent input. This could be verified by analyzing the Entropy of the child input set.
2.5 - Test suite
Like I said above, finding a good program to test is hard. I tested a lot of programs (who, pdfinfo, libpng, ffmpeg, pdf2svg, md5sum, mpg123 and gif2png)
I definitely haven’t had the time to test more programs, but I will do after the end of my internship, to see if my modifications really help Vuzzer. For now, I will just test two softwares that give “bad” results of exploration, and make a complete analysis of my improvement regarding Libjpeg.
Notice that those programs are “bad” regarding code coverage exploration, but not about finding a bug. At some point, even if there is no exploration evolution for hours, Vuzzer can trigger a bug by input mutation. They are just “bad” in the sense that I can’t make conclusions about them regarding my improvements.
2.5.1 - Mpg123
I tested it during hours, but the input execution process is very slow, and with Pin and Libdft taint analysis it even slower. I made it 3 times, and both Vuzzer found a mutation at first loop, that made them stuck at a block count for the rest of 11 loops.
2.5.2 - Pdfinfo
I tested pdfinfo, but this sample is not very interesting regarding code coverage evolution. Because the original version of Vuzzer and my version didn’t find any new block after 22 loop turns (always 243 blocks on both sides).
2.5.3 - Libjpeg
So Libjpeg with the original Vuzzer was about ~1140 blocks after 11 loops on 3 tests. I made another test to see if this was still right, and with this new one the average is about ~1135 blocks with the 3 others test. This slightly change the basic statistics, but anyway those values are close. And this last test goes up to 45 loops about 1161 blocks, so I will use it as a comparison for a long test time (Libjpeg results with original Vuzzer).
2.5.3.1 - Action optimization and comparison reimplementation
Now the new Vuzzer, with the action optimization and the cmp reimplementation produces this result (Libjpeg results with action optimization). Like my first conclusion, removing “deleting” and “adding” actions were good improvement, because now Vuzzer is about 1167 blocks at 11 loops. And for a long test after 34 loops, it’s about 1183 blocks, compared to 1160 on the original version.
Note that my test took way longer than the original version, it’s due to Libjpeg. Because there are inputs (images) that took 5 minutes to be interpreted by Libjpeg. So in those conditions (with Pin that handles the execution), the processing of those inputs is about 15-20 minutes per input. This waste of time is triggered randomly my Vuzzer’s mutation, so it’s difficult to conclude something about it.
But why this didn’t appear in the original Vuzzer ? My theory is that because my last test didn’t travel those blocks, if we look at the code coverage of the original Vuzzer test, it stops about 1161. But my Vuzzer goes way longer than that, and about 1171 basic blocks, loops in my Vuzzer start to take 1 hour each instead of ~8 minutes before it reaches 1171. We don’t know if this is the issue, and we can’t know without analyzing the input and check the trace.
My supervisor told me that they faced the same issue during their test, so this slower loop is not due to my modifications. This issue could be verified by using IDA Lighthouse, but I haven’t had enough time to really check a specific case like this one.
2.5.3.2 - Child input algorithm and AFL-CMIN reductions
Sadly, child input generation doesn’t seem to not help Vuzzer in terms of exploration, and only makes a difference of 1-3 blocks occasionally. This was confirmed by AFL-CMIN results (Code AFL-CMIN input selection), there is less good inputs generated by the child input creation than the normal input generation. ALF-CMIN found that ~20% of common generated inputs (500 inputs) are good, and only ~1% of generated child inputs (1000 inputs) travel long paths. So, child inputs are accurate regarding conflict handling, but inaccurate regarding exploration.
The explanation could be that I’m applying a mutation of a parent to each child inputs, no matter if they are created by this parent. This is an error and can make child inputs “too modified” and fail in error handling. There are still child inputs that travel new paths in the executable, so this could be just a question of test program. I think they are still good enough to trigger bugs, and if I fix this issue, Vuzzer could produce better results from this algorithm.
AFL-CMIN is a good way to reduce the input number to test, and only use inputs that really cross a lot of blocks. The improvement is more about the time saved and the accuracy of tested inputs than the exploration. So this improvement can’t be seen from Vuzzer results unless we consider the time as something stable to make conclusions (see Base statistics).
2.6 - Todo list
So there are still a lot of things to do for this project, and will definitely continue it after the end of my internship.
Here is a short list of remaining actions :
-
Implement IDA Lighthouse code coverage exportation, I tried to implement it, but Lighthouse seem to need a special version of Intel Pin4, and the version used by the current Vuzzer is 3.7 (not the latest).
-
My pattern system could be improved with more variables / functions, multiple arguments / behavior for a variable or operators for example.
-
The child input algorithm could be improved by doing a filter of applied mutations, to only apply relevant modifications.
-
Some ideas of others actions could be implemented like “change_bytes_to_string” or “change_bytes_to_utf8”.
-
Fix the fitness score selection, and improve memory file inputs.
-
Fix the child input mutation, to apply mutations on children made by its parent, and not the entire child set.
3 - Conclusion
I improved Vuzzer regarding its performances, and I think my work could help its users to perform better tests. This project was coded by a lot of contributors, and I made my features opened enough to be modified and improved in the future.
Because of its research aspect, it was difficult to define an end date for my contribution. But I made it in time regarding my internship time period. This project improved my knowledge of python, and regarding my reverse engineering skills, familiarized me with fuzzing techniques and their implementations.
3.1 - Good config
Sometimes, everything is about a good configuration. I made my improvements flexible, so everything can be configured like the old Vuzzer. And I saw during my tests that a config should be made for each target program. Sometimes doing too many mutations per input makes Vuzzer stuck in the same traveled path, sometimes apply taint-based changes to child inputs produces better or worst results. A big population size doesn’t mean that you will travel more paths in the executable, so tester should find the correct input count that allows a fast taint analysis post loop. And child creation randomness could be good or bad in function of the test application. In a nutshell, to get good results can be a question of configuration.
3.2 - Is my improvement effective ?
Well, if we look at my tests on my only sample Libjpeg, yes, my improvement seems to be effective. Vuzzer traveled a deeper path in the target program, faster than it did before. But I need to test my improvements on more samples, and on a more powerful computer to really know if Vuzzer is “always” performing better now.
Fuzzing is too random to be fully understandable, by this I mean that Vuzzer creates random inputs, those inputs cross random paths in the executable, and the comparisons made by the executable are differents each time we launch it on an input. And this concerns only one target program, and considering that each program is different, this adds a new level of randomness.
My goal was to increase code coverage of generated input. With regards to this, I did well, but it doesn’t mean that Vuzzer will always do things right about that randomness mentioned above. The current state of things is, Vuzzer is able to explore deeper path than it did before, by creating more legitimate inputs. But, in some cases, if Vuzzer explores a deep path in the executable, without knowing that it’s an error handling, it will improve its false inputs to be handled better by the software.
So my improvements are based on facts and assumptions at the same time, and will remain like this, no matter the improvements we do. But because code coverage is the only thing we can try to improve regarding the current Vuzzer strategy : yes, increasing that element is right, and yes, Vuzzer should be better now with my improvements.
Like I said, fuzzing is too random to be fully handled, and we can just try to make effective strategies, to improve something based on randomness.
3.3 - End words
Fuzzing is something very interesting that will, and need to be improved in the future, to help cyber security to evolve like the computer science does. And I hope that my work will help its contributors.