🔥 Quick look around VMP 3.x - Part 2 : Code Mutation
Hi
Here is my short research about VMP mutation engine.
VMProtect is a well known protection with a lot of features, its core one is its virtualization engine. It’s a very good and optimized one, even if elite crackz say that it’s not at the level of Themida. Cracking its virtualization engine is time consuming, so I’m not specialy focused on it right now. But there is another feature of VMP that is interesting for me, its code mutation engine. Its basicaly a way to change the form of the code, without changing its purpose. As there is multiple way to do one thing, VMP mutate the code so it’s still the same, but with a different signature.
Note : I used VMProtect 3.5 demo version for me tests.
Introduction
First of all, know that you need to mark all functions that you want to mutate, in the code (call to VMProtectBeginMutation), or from the VMP software (marking manualy from addresses or using PDB files). So to do a quick link to my Virtualization in commercial products post, if you just apply the protection without marking any functions (like some software do), VMP is useless.
To learn more about the code mutation, I made a template function and I mutated it 20 times.
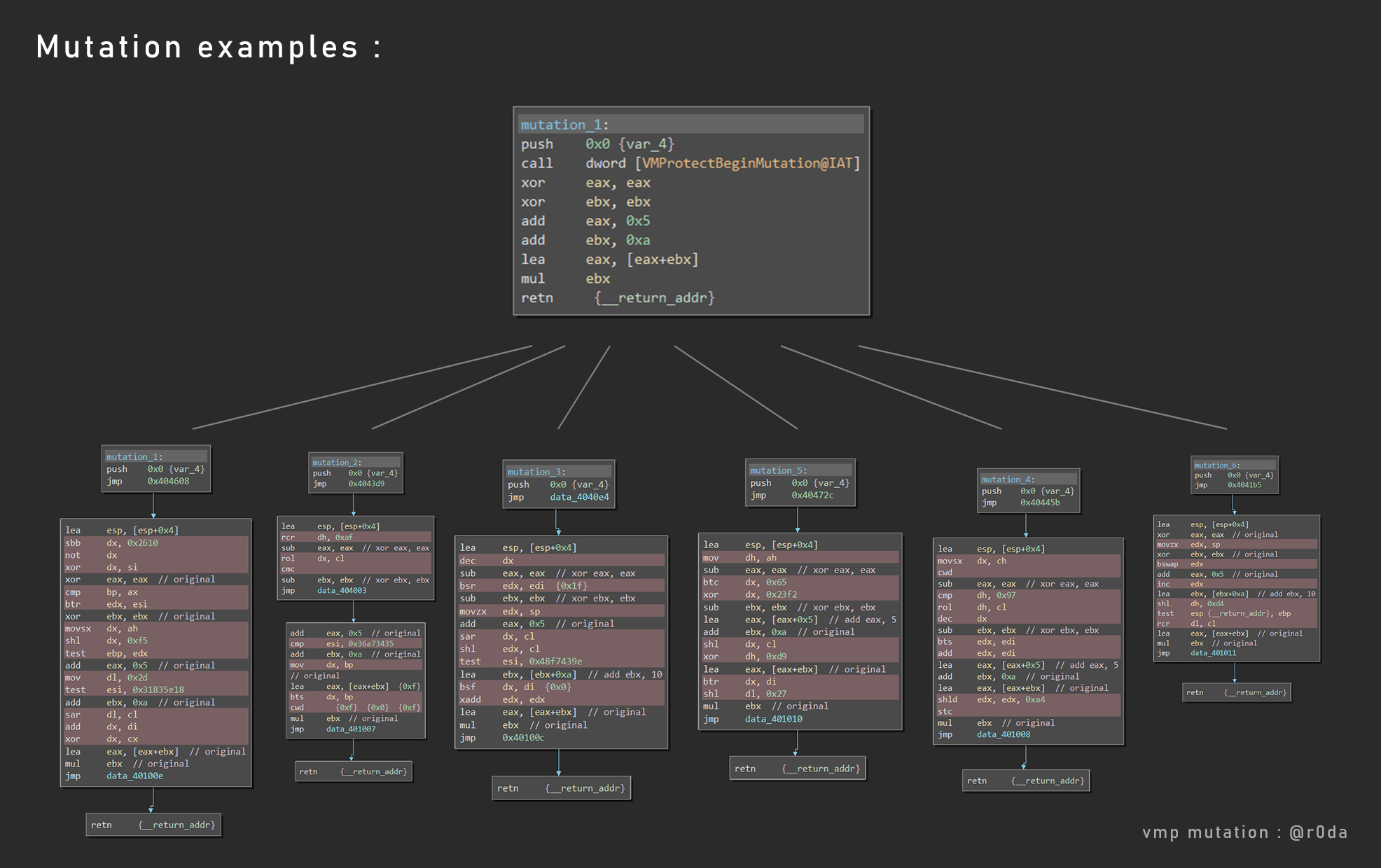
Each mutated function in the code section is jumping to a VMP section that contain the next code to execute. Because modifing (insertion) the original code section made by the compiler is not doable without destroying the entire code structure. So VMP store all mutated functions in a new section to avoid size problems (see: Insert Code in PE).
VMP mutation is a combination of a lot of tricks, code mutation, junkcode, control flow and block unalignment.
Junkcode and mutation
When I start looking into it, I was really surprised to see that VMP is not focused on mutating original instructions. Original instructions are only mutated 1/2 (based on what I’ve saw, could be wrong about it).
However, it’s not a bad thing at all, VMP is known for its research about optimizion. And if they do real code mutation 1/2, there must be a reason.
Anyway, the main thing that change when you compare mutated functions is the junkcode insertion.
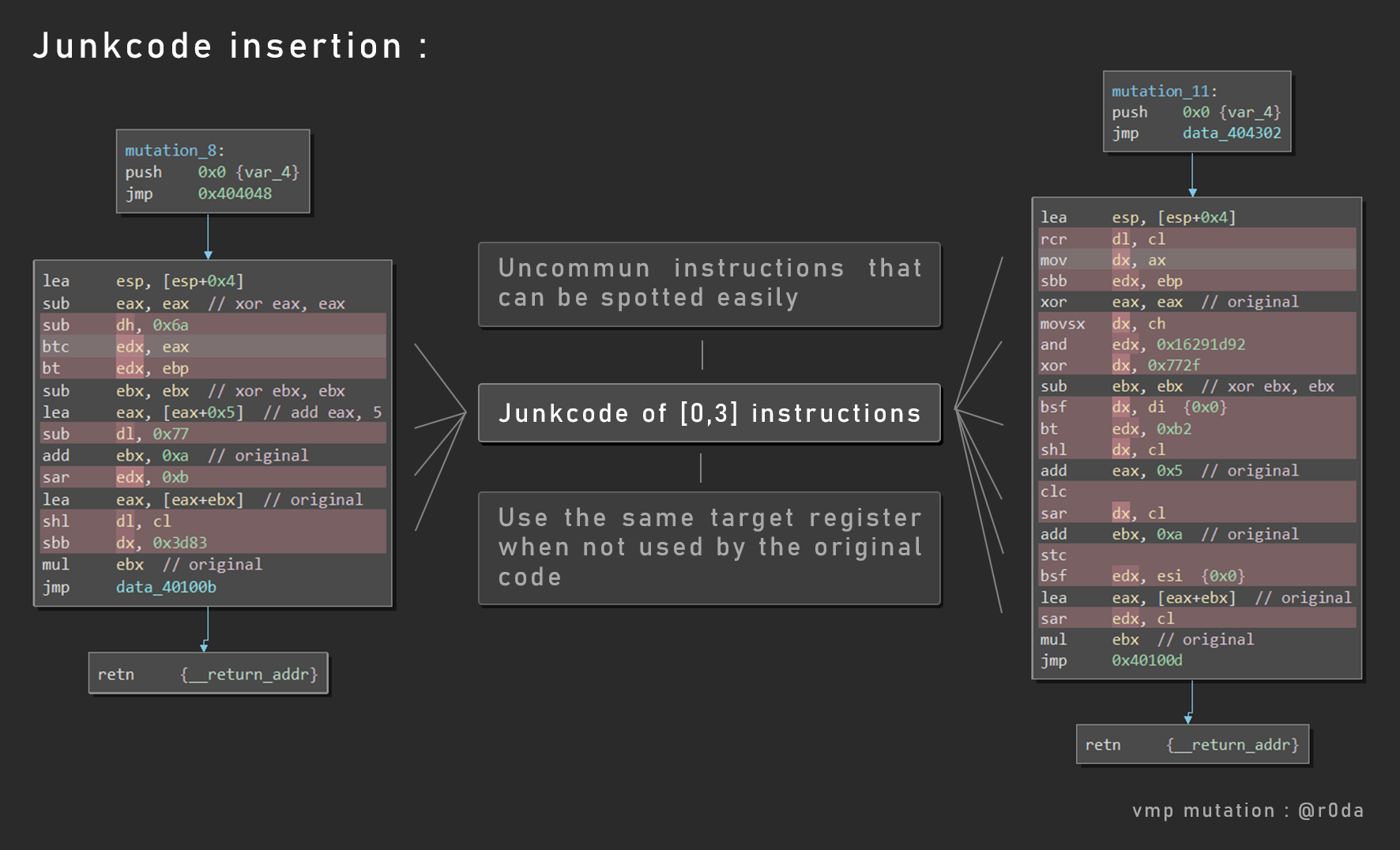
You can see in red junkcodes, it’s inserted after each original or mutated instructions. The number of junk instruction is between 0 and 3. Frequently, junk instructions that follows the original instruction use a register that will be overrided by the next original instruction.
Also, as you can see, instructions used by the junkcode generation are uncommun, and you can spot them easily. For exemple : rcr, bt, btc, sbb, lahf . . .
Here are the instructions that VMProtect uses the most to mutate code :
["cwd","stc","rcl","cdq","setb","nop","cmovge","setae","sete","rdtsc","cmovs","sbb","setl","setno","cmovo","setbe","cmovl","cmovae","btc","cwde","cdq","cmovg","seta","cmovnp","shld","cmova","cmovp","shrd","bsf","clc","cbw","rcr","btr","stc","adc","cmc","cmovle","bt","bts","bsr","setge"]
There are some pure junkcode insertion like mov, xchg, cmp on the same register, nops and operations on a register that will be reset right after by the real instruction. About eflags, we could see some resets using double cmp or test calls.
Regarding the original instruction mutation, we can observe things around lea instruction like mov eax, ebx to lea eax, [ebx], add eax, 3 to lea eax, [eax + 3] or sub eax, 5 to lea eax, [eax - 5]. Also things like xor eax, eax translated to sub eax, eax or mov eax, 0. And that’s it, and it’s powerfull enough regarding its realistic junk insertion.
Control flow
Like I said, VMP use control flow protection. It’s focused on jumps across all basic blocks and not conditional jumps, so the original control flow could be visible even after mutation.
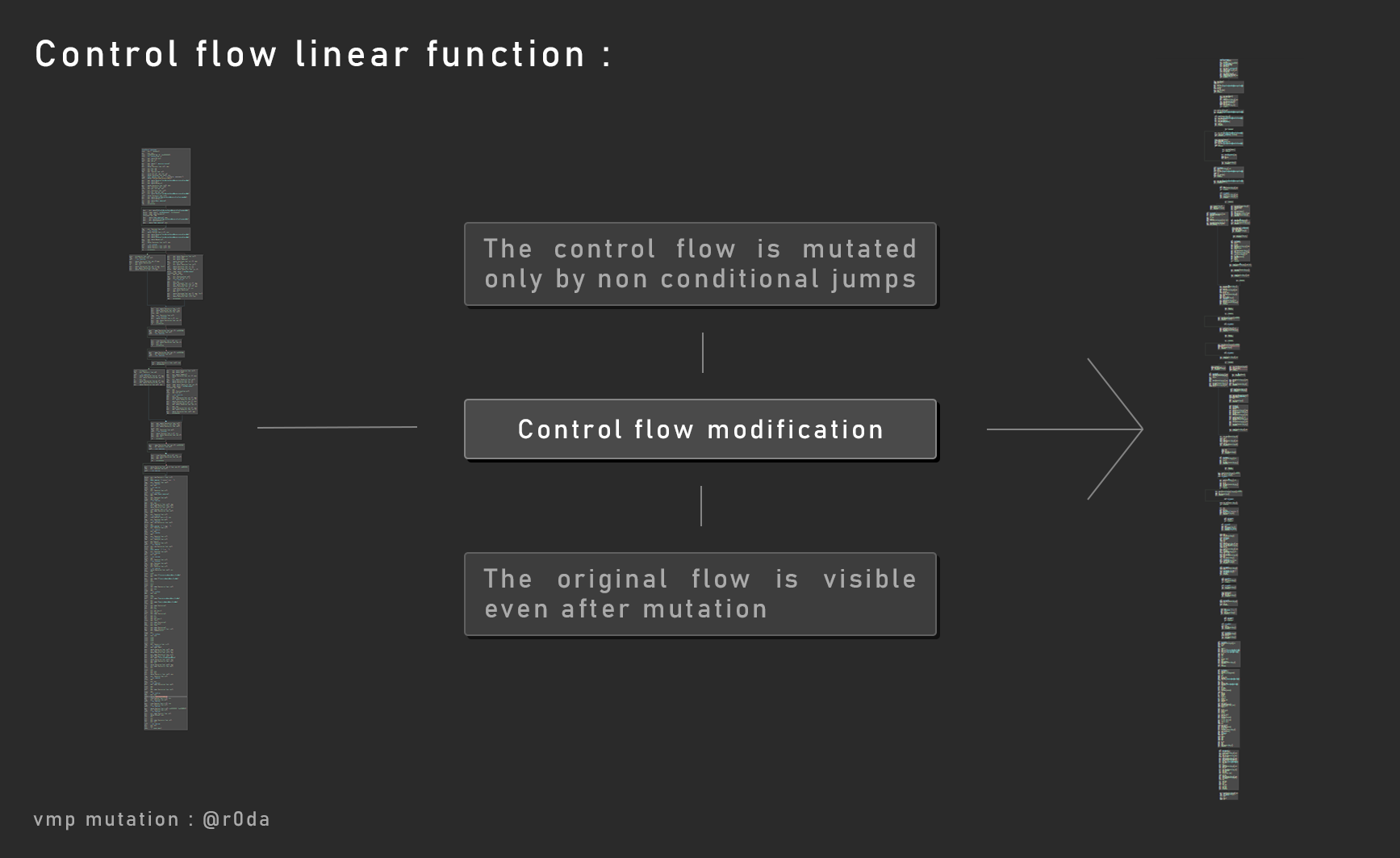
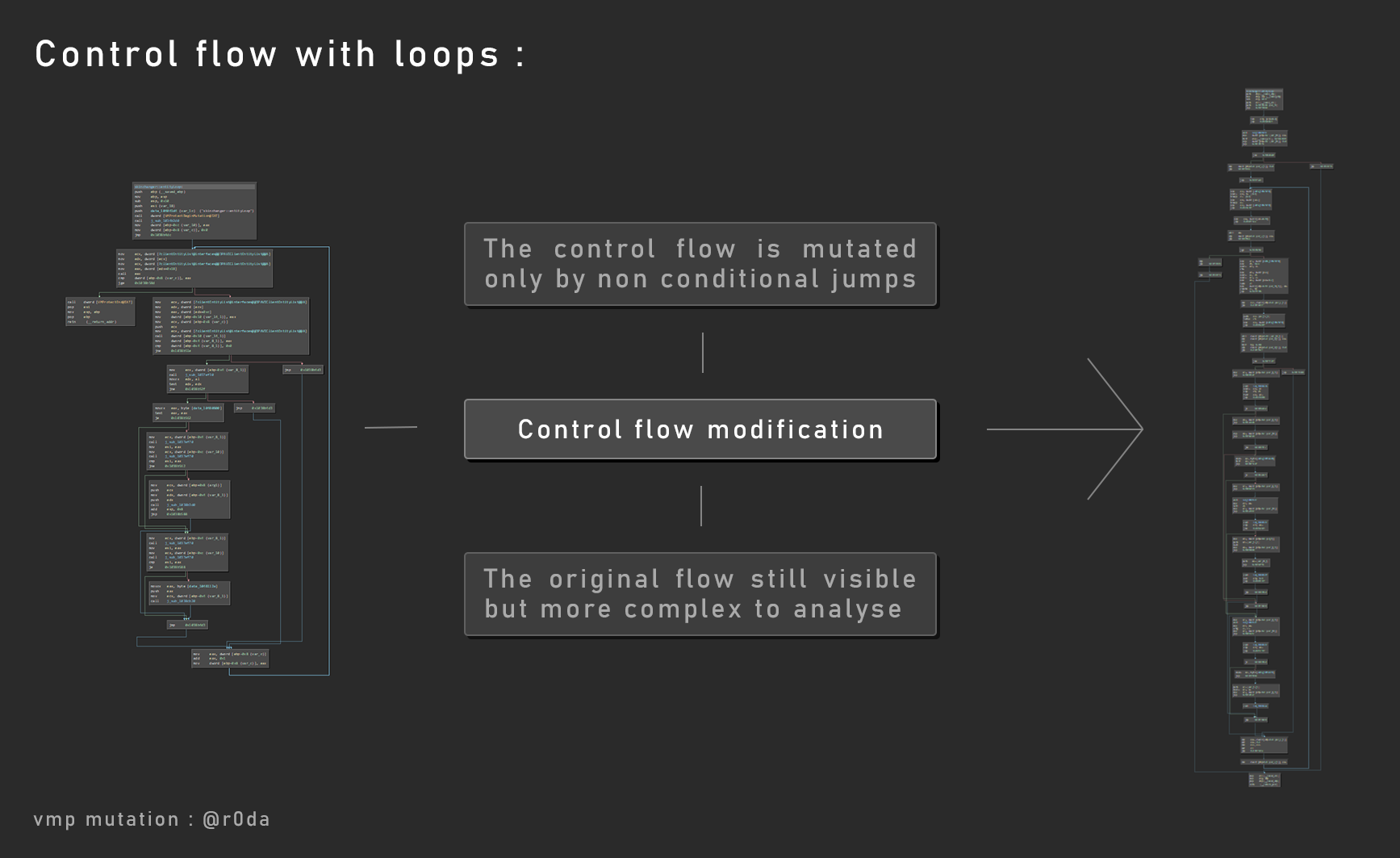
Block positioning
About the control flow, each basic block (code block) is placed in a certain maner with the goal of trick the reverser.
Function splitting
Let’s illustrat with a code section, here in dark grey :
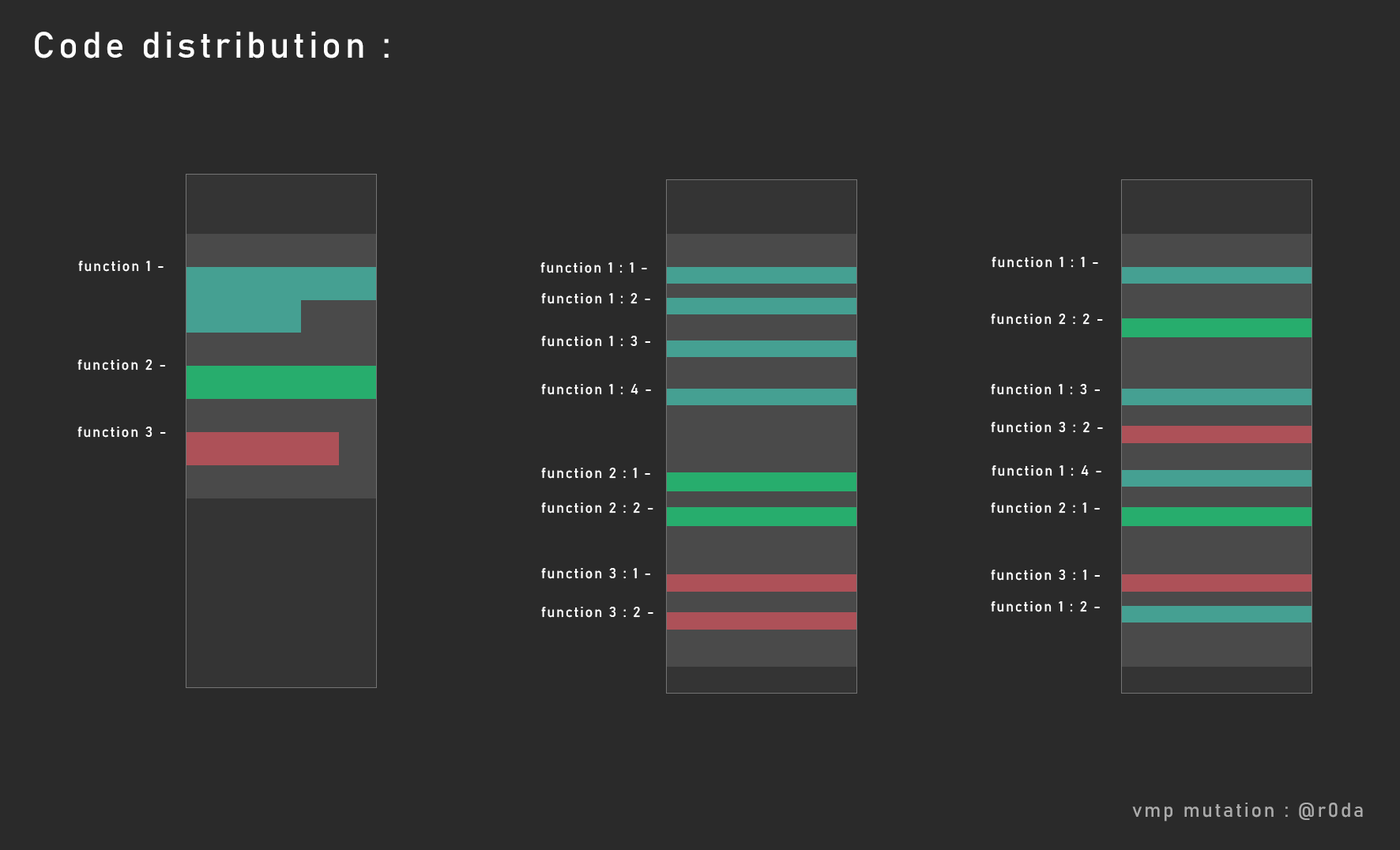
As you can see on the first part, the instructions are melt in one block as functions.
The part in light grey is the padding (null bytes or 0xCC int3 instructions) between functions in the code section. This padding is produced by the compiler to follow the Function Alignment (see: Insert Code in PE).
Block unalignment
In addition to function splitting, VMP use random sized paddings between codes. For exemple, here is an alignment that could be created by a compiler.
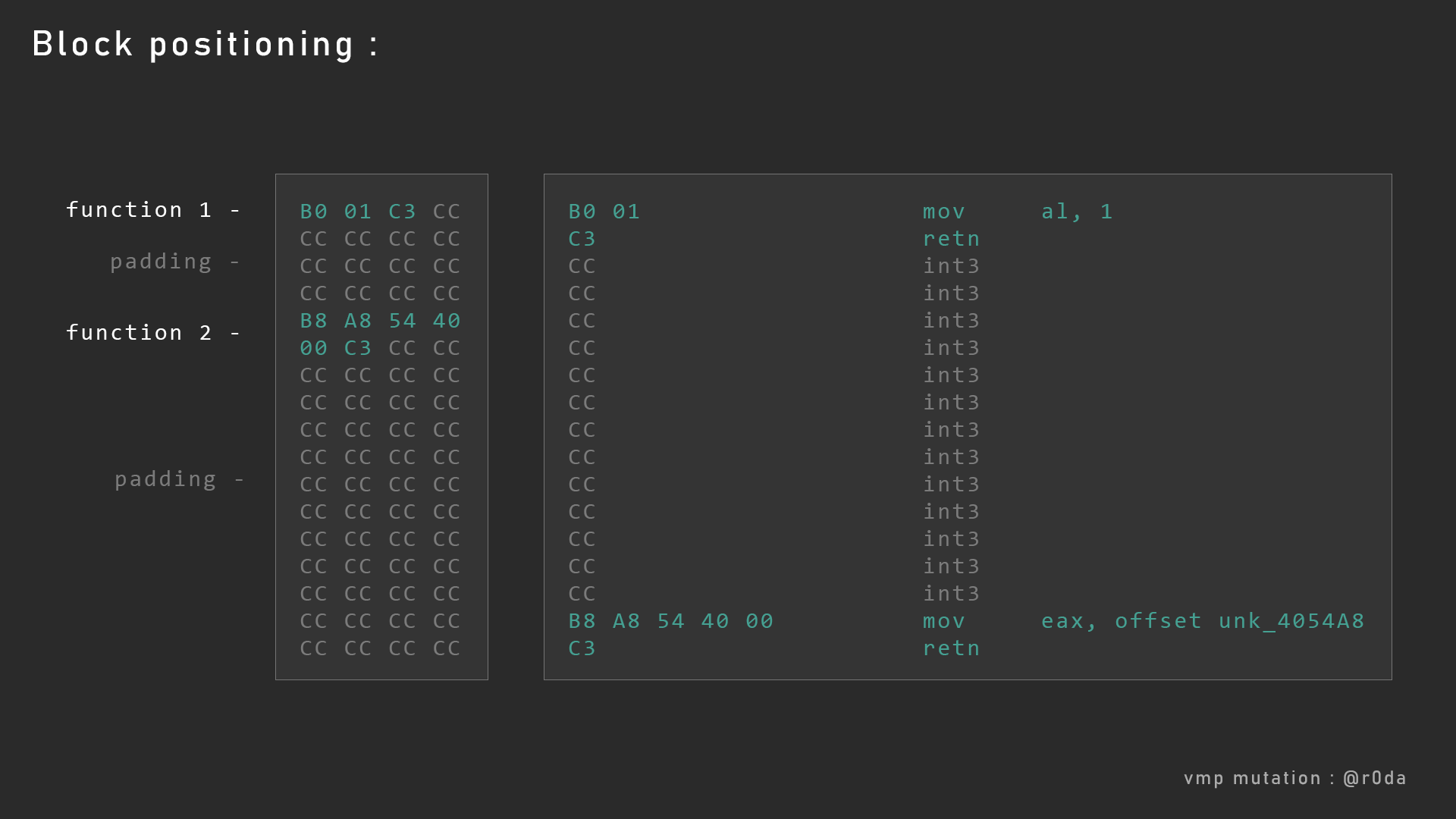
As you can see, the first in green is followed by 0xCC bytes, it’s a one byte instruction that produce a debug even if executed. In this case it’s not supposed to happend, but this one byte instruction keep the “aligment” of each next executed code (see the begin of this post if you have trouble to understand)
Next, let’s take a look at the alignment of VMP mutated code :
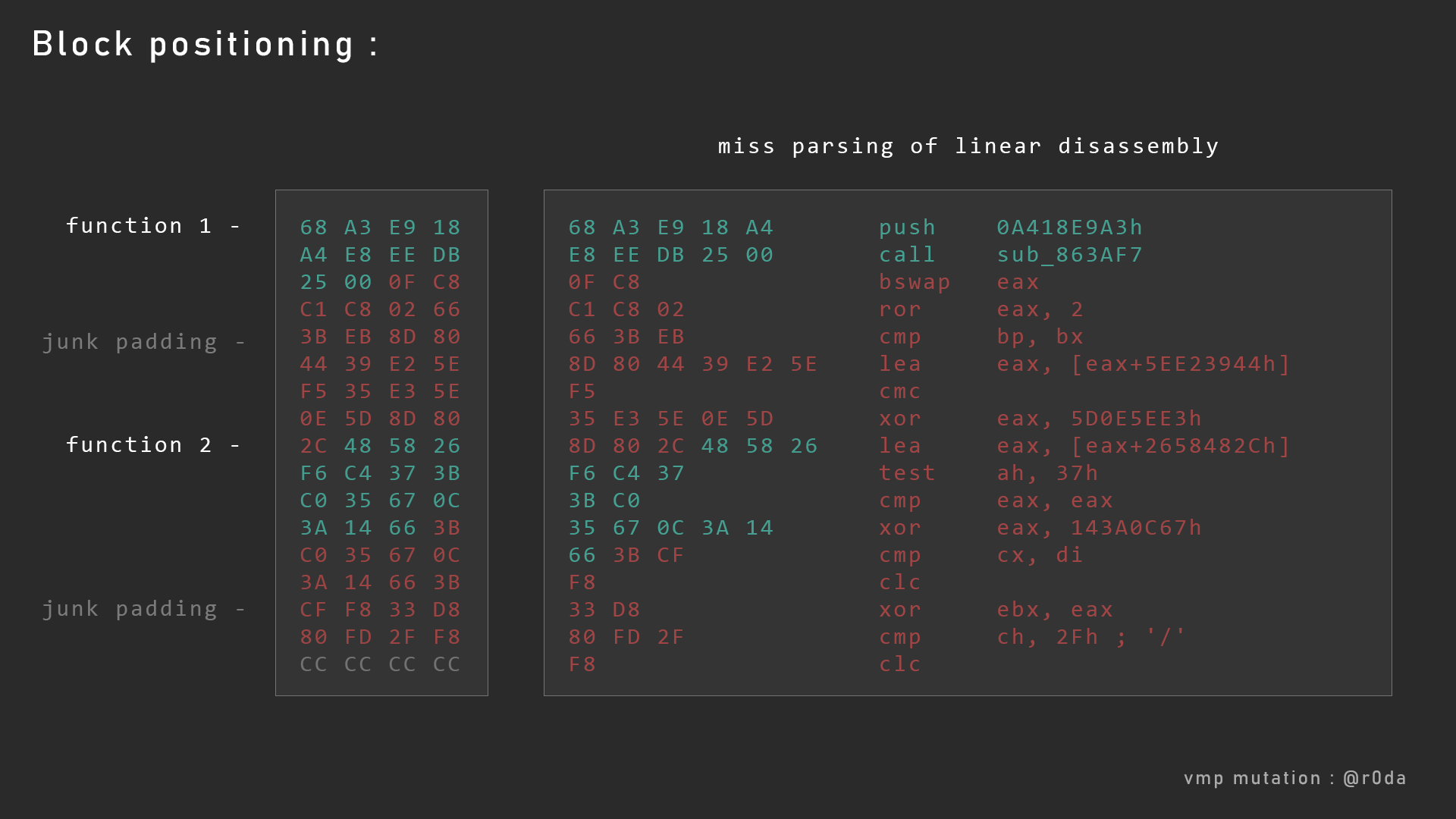
Here the first code in green is executed, but at some point, it will jump to somewhere in the code (the second part in green), but we don’t know where. So the code below the call sub_863AF7 will never be executed, but the dissasembler don’t know it and dissasemble it anyway. And it’s junk padding ! random data to fool the dissasembler. And as you can see with the code in red, it’s completly wrong.
This is the right way to dissasemble it :
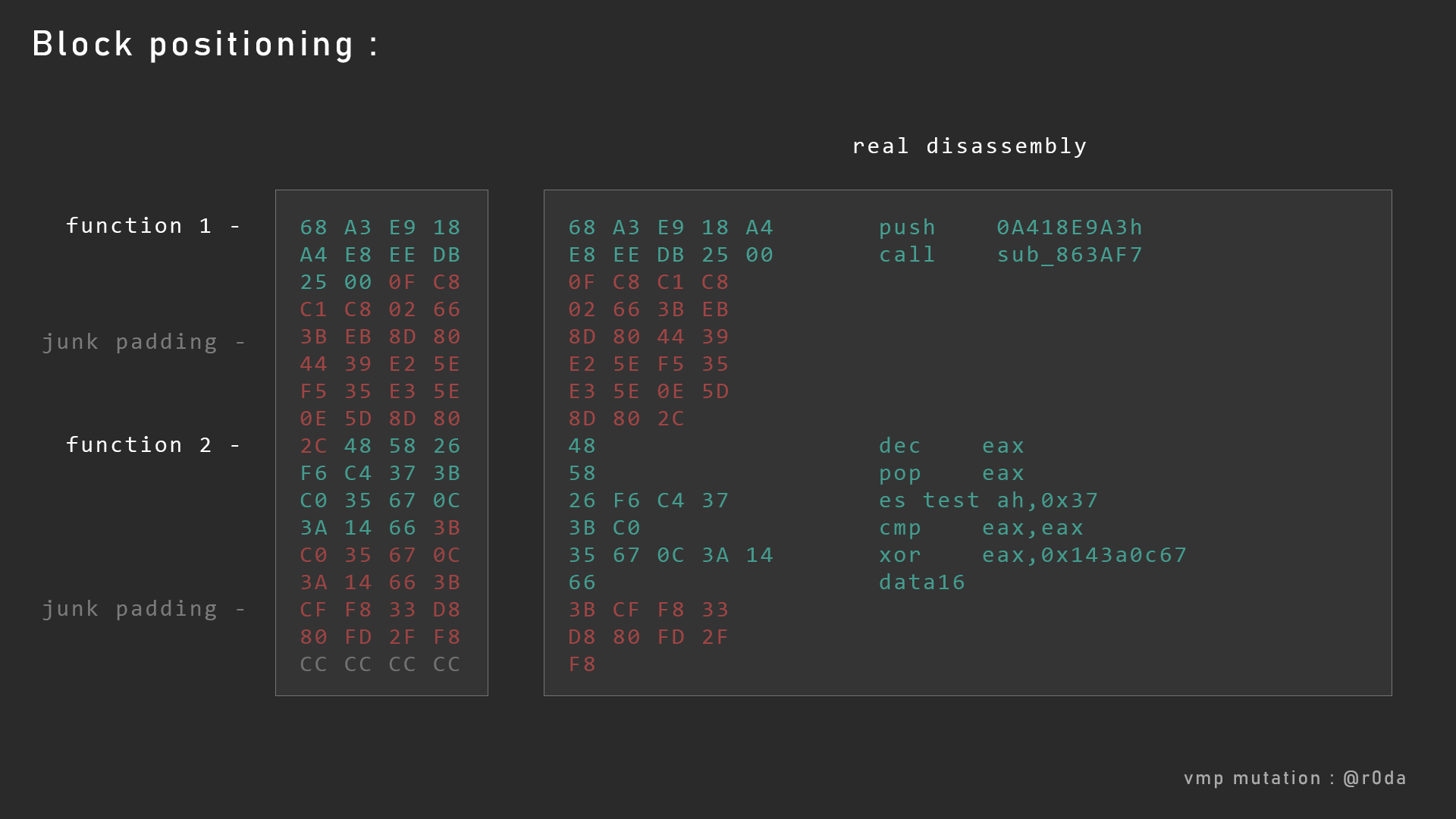
But to know that, we have to launch the executable and follow the flow of its execution to mark all the travelled blocks.
Concrate example
In a concreate example, here a C++ function. We still notice that the mutation is focused on control flow, but the code stay readeable. The junkcode uses registers that will be reset by the next “real” instruction, so the program is not broken.
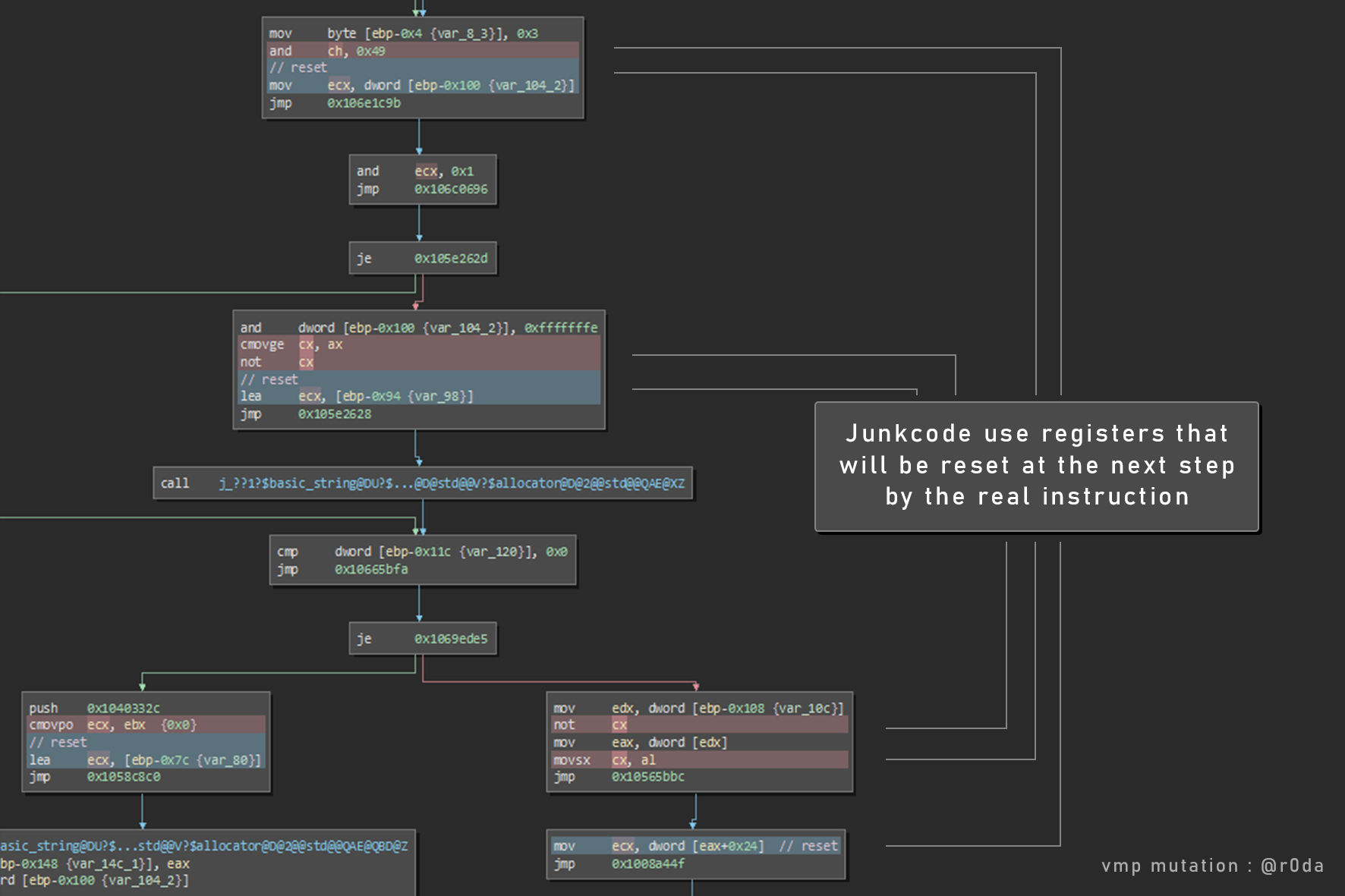
How to get rid of it ?
Well, if you want absolutly to remove it, first you can code a tool to remove instructions that play with a register and reset it right after. After you can remove useless instructions like movs and cmps on the same target and other things I said previously. Another idea could be remove uncommon instructions, but it could be dangerous if the real program do some tricky operations. Last approach is data tracing or dynamic taint flow analysis, by tracing the behavior of registers and their data, we are able to define what is junkcode. Using symbolic emulation, you can remove useless instruction with frameworks like miasm or triton (see the exemple here)
Conclusion
VMP is impressive, and its mutation engine could make reverse or devirtualization process way longuer that it should, even if the junkcode could be spotted. With high performance optimizations, the junk instructions could be hard to split from the real code in so cases (C++ and other virtualized stuff). In Ultra Mode (mutated code virtualized), this mutation should be a pain when you have to devirtualize the opcode.
Regarding code signature, it’s perfect, if you want to make your code different without adding useless junkcode it’s one of the best solution. Personaly I’m using it to bypass signature checks of Anti-cheats, but you could use it for some other mean ways x)
UPDATE : After being a while in virtualized VMP routines (which are mutated), I think they should use more traditional instructions and commom registers. Because otherwise you can spot the junkcode easily, they have the ability to know which register size is used in the code context, and they should keep the same “flow” of data manipulation size instead of switching from eax to al and return back to ax.